5.6 Imaging with OBIT, Complex imaging
AIPS contains “verbs” that access programs in the OBIT software package written by Bill Cotton (bcotton@nrao.edu). If
that package is installed on your computer, which is easy for Linux and not too hard for Mac systems, then you
may use these programs. Two of the verbs are used to translate EVLA data into 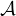
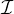
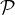
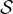 format; see §4.1.1. The other
four verbs provide increasingly elaborate access to OBIT’s imager program. They are called OBITMAP, OBITIMAG,
OBITSCAL, and OBITPEEL. The first images a field of view in a single scale, the second allows many
more imaging options including multi-scale, the third adds self calibration, and the fourth allows the
self-calibration to be direction dependent. The group cannot take responsibility for the OBIT
installation and programs, but much of the cleverness in was due to Bill and his later work
deserves consideration. If nothing else, the tasks will run in a multi-threaded fashion which does
not.
format; see §4.1.1. The other
four verbs provide increasingly elaborate access to OBIT’s imager program. They are called OBITMAP, OBITIMAG,
OBITSCAL, and OBITPEEL. The first images a field of view in a single scale, the second allows many
more imaging options including multi-scale, the third adds self calibration, and the fourth allows the
self-calibration to be direction dependent. The group cannot take responsibility for the OBIT
installation and programs, but much of the cleverness in was due to Bill and his later work
deserves consideration. If nothing else, the tasks will run in a multi-threaded fashion which does
not.
has a complex imaging option impletnted with the RUN file and procedure called CXIMAGR. It is a sequence of
tasks UVIMG, FFT, and CXCLN. It is interesting, but the normal imaging described in this chapter is likely to be more
satisfying.