10.2 Single-dish data in the “uv” domain
Once you have gotten your data into 
 , a wide range of tasks become available to you. In addition
to the single-dish specific tasks discussed below, these include data movement tasks (UVCOP, UVSRT,
DBCON), data averaging (AVER, UVAVG, AVSPC), non-interactive editing (CLIP, UVFLG), interactive editing
(SPFLG, EDITR, TVFLG), data backup and restore (FITTP, FITLD), and data display (PRTAN, PRTUV, UVPRT,
UVPLT).
, a wide range of tasks become available to you. In addition
to the single-dish specific tasks discussed below, these include data movement tasks (UVCOP, UVSRT,
DBCON), data averaging (AVER, UVAVG, AVSPC), non-interactive editing (CLIP, UVFLG), interactive editing
(SPFLG, EDITR, TVFLG), data backup and restore (FITTP, FITLD), and data display (PRTAN, PRTUV, UVPRT,
UVPLT).
10.2.1 Using PRTSD, UVPLT, and POSSM to look at your data
In the process of calibrating, modeling, editing, and imaging of single-dish data, there are occasionally problems
that seem to arise because users are not aware of the data that they actually have. PRTSD is the task for such users. It
displays the data with or without calibration for selected portions of your data set. This will help you identify what
pointing positions actually occur in your data, which channels are highly variable or bad, and the like. SPFLG,
UVPLT, and others are good for looking at the data set as a whole, but PRTSD really shows you what you
have.
To run it, type:
> TASK ’PRTSD’ ; INP C R | to list the required inputs on your screen. |
> INDISK n ; GETN ctn C R | to select the single-dish “uv” file to be displayed. |
> DOCRT 1 C R | to select the on-screen display at its current width; make sure
your window is at least 132 characters across for the best
results. |
> DOCELL -1 C R | to look at the data values; DOCELL > 0 causes the offsets that
have been removed (usually 0) to be displayed. |
> CHANNEL m C R | to display channels m through m + 5. |
> DOCAL FALSE C R | to apply no calibration. Note that the 12m off scans and
instrumental gains are applied by OTFUV; this parameter
applies only to any additional calibration contained in CS files.
See §10.2.3. |
> ANTENNAS a1,a2,… C R | to look at beams/IFs a1,a2,… only. |
> BPRINT bb C R | to begin the display with the bbth sample in the data set
before application of the other selection criteria (TIMERANG,
ANTENNAS, etc.) |
> NPRINT 2000 C R | to shut off the display interactively or after a lot of lines. |
> XINC x C R | to display only every xth sample of those selected by the other
criteria. |
> INP C R | to review the inputs. |
> GO C R | to start the task. |
PRTSD will start and, after a pause to get through any data not included at the start of the file, will begin to display
lines on your terminal showing the scan number, time, coordinates, and data for six spectral channels. After 20 or so
lines, it will pause and ask if you want to continue. Hit C R to continue or type Q C R or q C R to quit. If you decide
to get hard copy, set DOCRT = -1 and the output will be printed. To save the display in a text file, without printing,
set DOCRT = -1 and give the name of the file in the OUTPRINT adverb. See §3.2 and §3.10.1 for more information on
printing.
There are a number of tasks which plot uv visibility data; see §6.3.1. The most basic of these is UVPLT, which can be
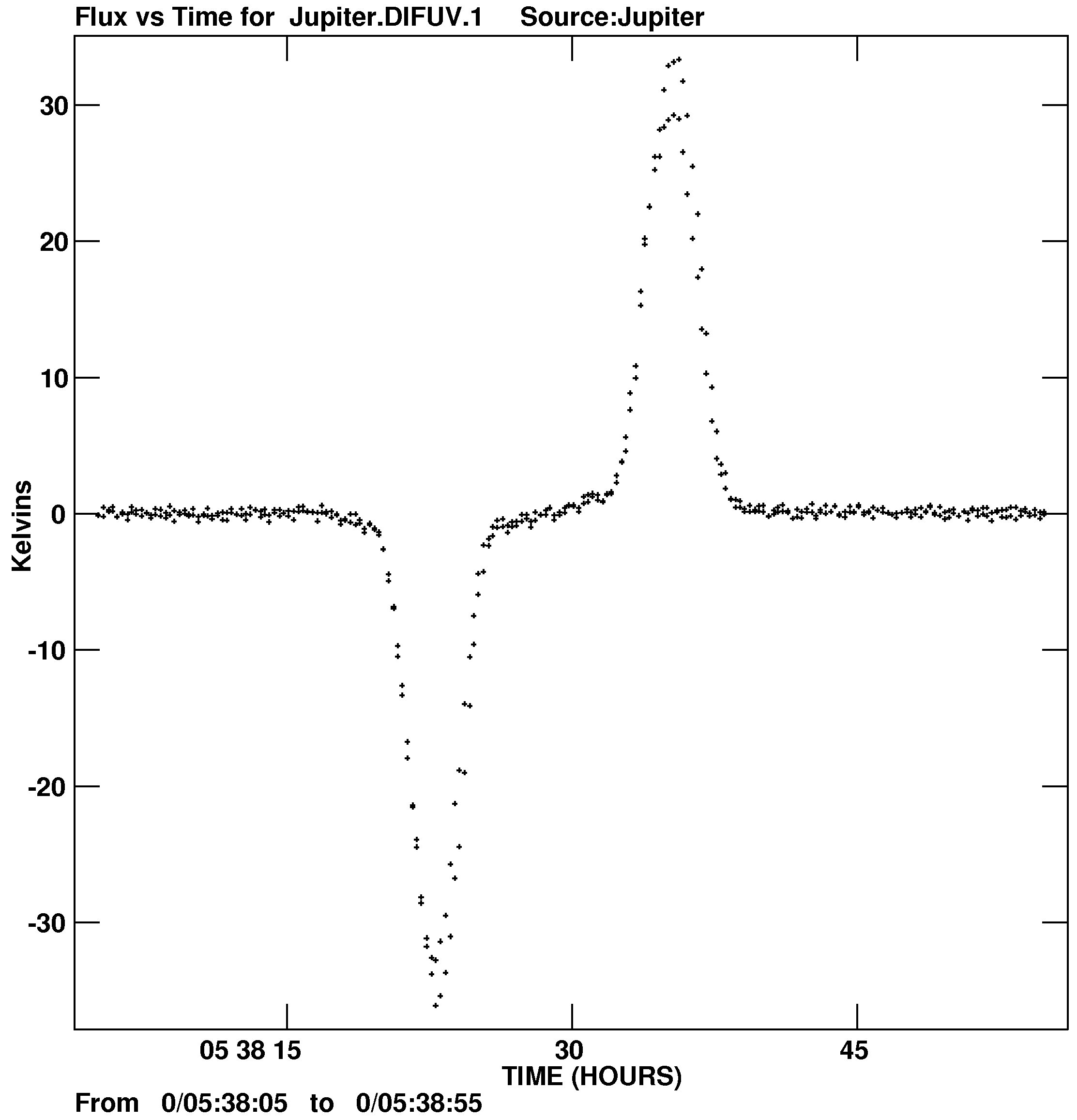
useful for single-dish data sets. For example, to generate the plot of flux versus time in 12m OTF beam-switched
continuum differenced data seen in the accompanying figure (Figure 10.1), the parameters given below were
used:
> INDI n ; GETN ctn C R | to select the disk and catalog entry of the data set. |
> DOCALIB FALSE C R | to apply no calibration; UVPLT does not understand
single-dish calibration. |
> BPARM = 11,9,0 C R | to plot time in hours on the x axis and flux in Kelvins on the y
axis. The other parameters can be used to specify fixed scales
on one or both axes, but are just self-scaled in this example. |
> XINC 1 C R | to plot every selected sample. |
> BCHAN 1 ; ECHAN 1 C R | to plot only “spectral channel” 1, the actual data values. |
> ANTENNA 1,0 ; BASELINE 0 C R | to do all baselines with antenna 1, namely 1–1 or, in 12m
nomenclature, IF 1.. |
> TIMER = 0, 5, 38, 5, 0, 5, 38, 55 C R | to restrict the times to a single scan. |
> DOCRT = -1 ; GO C R | to make a plot file of these data. |
After UVPLT is running, or better, after it has finished:
> PLVER 0 ; GO LWPLA C R | to plot the latest version on a PostScript printer/plotter. |
The second plot in Figure 10.1 was generated with BPARM = 6, 7 and shows where samples occur on the sky in a
different data set.
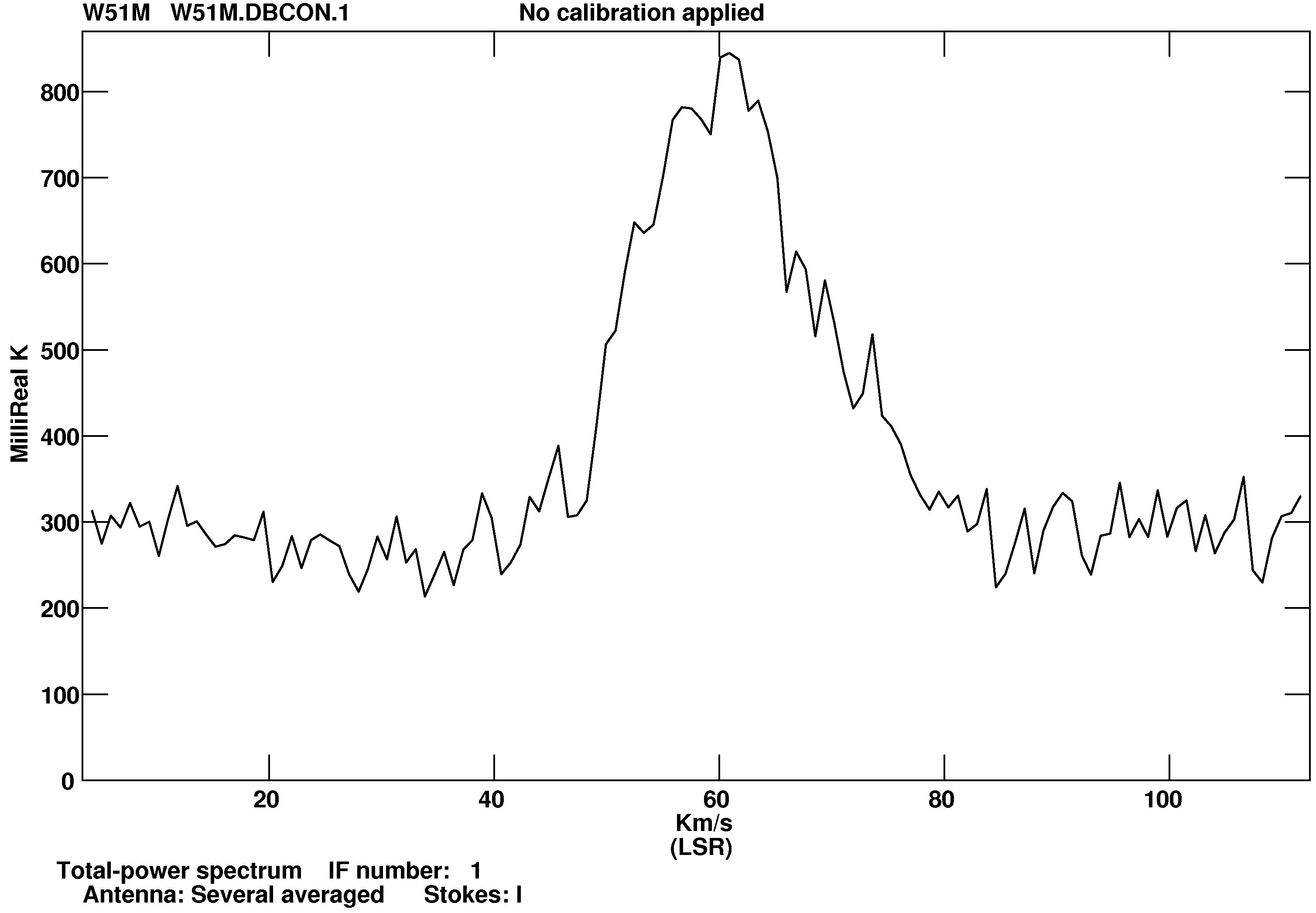
With spectral-line data, POSSM will plot observed spectra averaged over selected “antennas,” time ranges, and the
like. Thus,
> INDI n ; GETN ctn C R | to select the disk and catalog entry of the data set. |
> TIMERA 0 ; SOLINT 0 C R | to average all times into one plot. |
> APARM(7) = 2 C R | to have velocity labels on the x axis. |
> GO C R | to run the task. |
LWPLA was then used to make a PostScript version of the plot seen in Figure 10.2.
10.2.2 Using UVFLG, SPFLG, and EDITR to edit your data
Editing is the process by which you mark data samples as “unreliable” or “bad.” In , there are two methods
for doing this. The simplest is to have the editing software alter the weight of the sample to indicate that it is
flagged. If the data are not compressed, this is a reversible operation. If the data are compressed, however, then the
data themselves are marked as “indefinite” and the operation is not reversible. The second method is the use of a
flag (FG) extension table attached to your uv data set. This method requires that the data be sorted into time order
for large FG tables and is supported by most, but not all, tasks. Small (< 6000 row) FG tables may be used with
data in any sort order. If the task does not have the FLAGVER adverb, then it does not support flag
tables. However, since flag tables can be applied to the data by SPLIT, we use them in the recipes
below.
To sort the data into “time-baseline” (TB) order,
> INDI n ; GETN ctn C R | to select the disk and catalog entry of the data set. |
> SORT ’TB’ C R | to sort into time-baseline order. |
> ROTATE 0 C R | to avoid damage to the coordinates. |
> INP C R | to check the parameters, e.g., the output name. |
> GO C R | to run the task. |
The most direct flagging task is UVFLG, which puts commands into the flag table one at a time (or more than one
when read from a disk text file). To use this task to flag channel 31 from 7 to 8 hours on the first day of observation
from the second input (single-dish nomenclature) IF:
> INDI n ; GETN ctn C R | to select the disk and catalog entry of the sorted data set. |
> OUTFGVER 1 C R | to select the desired flag table. |
> TIMERANG 0, 7, 0, 0, 0, 8, 0, 0 C R | to set the time range from 7 to 8 hours. |
> BCHAN 31 ; ECHAN 31 C R | to flag only channel 31. |
> ANTEN 2, 0 ; BASELIN 2, 0 C R | to select “baseline” 2-2, the 2nd IF in 12m nomenclature. |
> APARM 0 C R | to ignore amplitude in flagging. |
> REASON ’Bad channel’ C R | to store away a reason. |
> INP C R | to check the full set of adverbs. |
> GO C R | to add one line to the flag table, creating one if needed. |
Multiple runs of UVFLG may be done to incorporate what you know about your data into the flagging table. Use
PRTSD and the plot programs to help you find the bad data. If you have a long list of flagging commands, you may
find it easier to use the INTEXT option of UVFLG to read in up to 100 flagging instructions at a time from a free-format
text file.
The task CLIP is popular on interferometer data sets since it automatically flags all samples outside a specified flux
range without interaction with the user. This blind flagging is often acceptable for interferometer data since each
uv sample affects all image cells so that the damage done by a few remaining bad samples is attenuated by all the
good samples. However, a bad sample in single-dish data affects only a few image cells and is hence not attenuated.
Thus it is important to find and remove samples that are too small as well as those that are too large. For this
reason, we do not recommend CLIP, but suggest that you look at your data and make more informed flagging
decisions.
The best known of the interactive editing tasks is TVFLG (§O.1.6). This task is not suitable for single-dish data since
it displays multiple baselines along the horizontal axis. The data on these baselines are related in interferometry,
but, in single dish, they are from separate feeds or polarizations and hence neither numerous nor necessarily
related. For spectral-line single-dish data, the task SPFLG is an ideal task to examine your data and to edit portions if
needed. SPFLG is a menu-driven, TV display editing task in which spectral channel varies along the horizontal axis
of the TV display and time along the vertical. (The spectral channels for each interferometer IF are displayed
on the horizontal axis, but single-dish data in has only 1 of this sort of IF.) The data may be
displayed with as much or as little time averaging as desired and is very useful for examining your
data even if you do not think that editing is needed. The latest version of SPFLG is documented in an
Memo
which should be consulted for current details.
To run SPFLG, type
> INDI n ; GETN ctn C R | to select the disk and catalog entry of the sorted data set. |
> FLAGVER 1 C R | to select the use of a flag table on the input data. |
> OUTFGVER 0 C R | to write a new flag table including all flags applied to the
input data. |
> BCHAN 0 ; ECHAN 0 C R | to view all spectral channels. |
> DOCALIB FALSE C R | to inhibit interferometer calibration of your data. |
> IN2SEQ 0 ; DOCAT FALSE C R | to create a new, but temporary “master file” each time. |
> ANTEN 0 ; BASEL 0 C R | to include all “baselines.” |
> DPARM 0, 1, 0, 0, 0, 0.1 C R | to include autocorrelation data and to set the fundamental
interval used to average data into the master file. The defaults
for these parameters are not suitable for single-dish data. The
other DPARM parameters may be ignored since they can be
altered during the interactive session. |
> INP C R | to review the inputs. |
> GO C R | to begin the interactive display and editing. |
The task will then read your data to determine which times occur in the included portions (you may set TIMERANG,
restrict autocorrelations, etc.) and then construct a master grid file with spectral channel as the first axis,
pseudo-regular times on the second axis (gaps are mostly suppressed), and, if needed, baseline number on the third
axis. SPFLG tells you the size of the resulting file, e.g., SPFLG1: Basic UV image is 128 14079 pixels in X,Y
(Ch,T).
At this point, SPFLG selects an initial display smoothing time long enough to fit all of the master grid onto your TV
window. It then averages the data to this interval and creates a display not unlike that seen in Figure 10.3. Move
the TV cursor to any menu item (it will change color to show which has been selected) and press button D for
on-line help information or press buttons A, B, or C to select the operation. Normally, you will probably begin
by reducing the smoothing time (ENTER SMOOTH TIME menu option followed by typing in the new
smoothing multiple on your AIPS window). Note that the display does not change other than to add
an asterisk after the smoothing time to indicate that that will change on the next image load. This
behavior is to allow you to alter a number of choices before doing the potentially expensive TV display.
In this typical example, you would either ENTER BLC and ENTER TRC by hand and finally LOAD the
sub-image or you can do this interactively with SET WINDOW + LOAD. You may examine data values
(like CURVAL) and flag data with the options in the fourth column. Flagged data are removed from
the display. You may review the flags you have prepared, undo any that you dislike, re-apply the
remaining ones to make sure the display is correct, and modify the appearance of the display with
the options in the first column. The image may be shown in zoom only during editing in order to
give you greater accuracy in examining the data values and locations. If you are doing some time
smoothing within SPFLG, the DISPLAY RMS option allows you to view images of the rms rather than the
value of the time average. Such a display allows you to find excessively noisy portions of the data
quickly.
Finally, when you are done, select EXIT. If you have prepared any flagging commands, SPFLG will ask you
if you wish to enter them into your input data set. Answer yes unless you want to discard them or
you have set DOCAT TRUE to catalog the master file in order to use it for multiple sessions. If you set
OUTFGVER to zero, then the flag commands are put into a new flag table which can be deleted later if you
wish.
SPFLG is not useful on continuum data; the interactive editor of choice for such data used to be the task IBLED, but is
now EDITR. These tasks are also useful for spectral-line data in that they can display the average (and rms) of a
selected range of channels. The spectral averaging should let you see more subtle level problems than can be seen
on individual channels (i.e., in SPFLG). EDITR is a menu-driven, TV display editing task, but it does not use
grey-scales to show data values. Instead, it plots time on the horizontal axis and data value on the vertical axis. The
full data set for the chosen baseline is displayed initially in a potentially crowded area at the bottom
of the TV window. This area is available for editing. If DOTWO is true, then it also displays above the
edit area a second observable (initially the difference between the amplitude and a running mean
of the amplitude) for the primary baseline. EDITR allows you to display up to ten other “baselines”
(e.g., 12m-antenna IFs) in frames above the active editing frame. These should speed the process of
editing and guide you in the choice of flagging one or all baselines at the time of the observation. A
smaller time range or window into these full data sets may be selected interactively to enable more
detailed editing. Be sure to set SOLINT to specify an appropriate averaging interval. Unlike SPFLG,
no further time averaging is possible. The menu options allow you to work your way through all of
your data, selecting time windows and baselines as desired. Consult §5.5.2 for more details about
EDITR.
EDITR has the ability to display a second data set for reference in parallel with the one being edited. This option is
likely to prove useful for beam-switched continuum observations. Select one of the beam throws for
editing and the other for reference display. Then, if editing is required, reverse the roles. It may also be
useful to look at your beam-switched data in its differenced form. The task DIFUV may be used to
difference the plus and minus throws, followed by EDITR (or any other uv-data task) to look at the
differences. Be sure to tell DIFUV that the time difference between the plus and the minus beam throws
should not be considered significant, i.e., SOLINT = 1 / 8 / 60 or a little bit more to avoid round-off
effects.
10.2.3 Using CSCOR and SDCAL to calibrate your data
The current calibration routines for single-dish data in are fairly rudimentary. The concept is similar to that
used for interferometers. Corrections are developed in an extension table (called CS in single-dish, CL in
interferometry) which can be applied to the data by some tasks. In particular, the single-dish tasks PRTSD and SDGRD
are able to apply the CS table to the data without modifying the data as stored on disk. They do this using the DOCAL
and GAINUSE adverbs. Other uv tasks, designed primarily for interferometry, also use these adverbs, but do not
understand or apply CS tables. For such tasks, you should carefully turn off the calibration option. If you do not,
such tasks will fail.
There are two tasks which can create CS tables: SDTUV discussed above and INDXR. To use the latter,
enter
> INDI n ; GETN ctn C R | to select the disk and catalog entry of the data set. |
> CPARM T1, T2, ΔT C R | to set the largest gap (T1) and longest scan (T2) times expected
in the data set (for the index table) and to set the time interval
(ΔT ) in the CS table, all in minutes. |
> GO C R | to run the task to create an index (NX) and a calibration (CS)
table attached to the main data set. |
Note that this task requires the data to be in time order and expects an antenna (AN) table. You may set CPARM(5) to
the maximum antenna number (beam number) in your data set and, with a few grumbles, INDXR will still create
and initialize a CS table when you do not have an antenna table.
At this writing, the CS table may be used to correct the recorded right ascension and declination (i.e., the pointing)
and to correct the amplitudes for atmospheric opacity and other gain as a function of zenith angle effects. To add an
atmospheric opacity correction to the CS table produced by INDXR, type:
> GAINVER 1 ; GAINUSE 2 C R | to modify the base table, producing a new table. |
> OPCODE ’OPAC’ C R | to do the opacity correction. |
> BPARM Oz, 0 C R | to specify the zenith opacity in nepers. |
> GO C R | to run the task. |
Note that CSCOR only writes those records in the output file that you have selected via TIMERANG, ANTENNAS, etc. To
make a new CS table to work for the full data set, you should first use TACOP to write the new table and then set
GAINVER and GAINUSE to both point at the new table. CSCOR needs to compute the zenith angle and therefore needs
to have an antennas file. If your data set does not have one, you may give the antenna longitude and latitude in the
CPARM adverb. The other operations offered by CSCOR are GAIN, PTRA, and PTDC which apply as second-order
polynomial functions of zenith angle corrections to the gain, right ascension, and declination, respectively. The
format of the CS table allows for an additive flux correction as well. There are no tasks at this time to determine such
a correction.
The basic single-dish tasks PRTSD and SDGRD can apply the CS table to the data as they read them in. Other uv tasks
which are more directed toward interferometry data cannot do this. If you need to use such tasks with corrected
data, then you must apply the corrections with SDCAL and write a new “calibrated” data set. To do
this:
> INDI n ; GETN ctn C R | to select the disk and catalog entry of the data set. |
> TIMERA 0 ; FLAGVER 1 C R | to do all times and apply any flagging. |
> APARM 0 C R | to do no averaging of spectral channels. |
> GO C R | to run the task. |
The output file from SDCAL can then be fed to UVPLT, SPFLG, or any other uv-data task including of course PRTSD and
SDGRD.
10.2.4 Using SDLSF and SDVEL to correct your spectral-line data
It may be convenient to remove a spectral baseline from each sample before the imaging step. Doing so may allow
you to skip the removal of a spectral baseline from the image cubes (as described in §10.4.1). To do this,
type:
> INDI n ; GETN ctn C R | to select the disk and catalog entry of the data set. |
> NCOUNT 1 C R | to solve for a slope as well as a constant in the baselines. |
> DOALL 1 C R | to fit a single baseline to all samples taken at a particular time.
This is useful for single-beam, multi-polarization data, but,
for multi-beam data, it is found that instrumental problems
dominate weather and require DOALL = -1 C R instead. |
> DOOUT -1 C R | to avoid writing a continuum data set. |
> FLUX 0 ; CUTOFF 0 C R | to write all data with no flagging. |
> CHANSEL s1,e1,i1,s2,e2,i2… C R | to use every i1 channel from s1 through e1, every i2 channel
from s2 through e2, and so forth to fit the baseline. Be sure to
avoid dubious channels, if any, at the ends and any channels
with real line signal. It is important to have regions at both
ends of the spectrum to fit the slope. |
> INP C R | to review the inputs. |
> GO C R | to run the task. |
You may, and probably should, use FLUX and CUTOFF to flag those data having excessive noise or excessive signals
in individual channels. These “excesses” are measured only in the channels selected by CHANSEL for fitting the
baseline.
If you have observed a wide field with relatively narrow spectral channels, there is an effect which you should
consider. The “velocity” corresponding to a particular frequency of observation depends on the velocity definition
(e.g., LSR or heliocentric), the direction at which the telescope pointed, the time of year, the time of day, and
the location of the telescope. Most telescopes adjust the observing frequency to achieve the desired
velocity for some reference time and position and many adjust the frequency periodically to account for
time changes. However, few, if any, can adjust the observing frequency for every pointing direction
and time in a rapidly scanned on-the-fly observing mode. The 12m telescope now sets the frequency
once per image with respect to the reference coordinate (usually the image center). In this mode, the
maximum velocity error in a 2 degree by 2 degree image is about 1.16 km/s (in LSR velocities) and
0.79 km/s (heliocentric). Since mm lines are often narrow, this can be a significant effect. Fortunately,
single-dish OTF data may be fully corrected for this effect so long as your spectra are fully sampled in
frequency. The task SDVEL shifts each spectrum so that the reference channel has the reference velocity for
its pointing position. The DPARM adverb array is used to tell the task how the telescope set reference
velocities and to ask the task to report any excessive shifts and even flag data having really excessive
shifts. The latter are to detect and/or remove times in which the telescope pointing was significantly in
error (i.e., high winds). DPARM(1) should be set to 0 for 12m data taken after 5 May 1997 and to 2 for
data taken before that date. The task VTEST was written to help you evaluate the magnitude of this
effect.
10.2.5 Using SDMOD and BSMOD to model your data
It is sometimes useful to replace your actual data with a source model or, if your continuum levels are well
calibrated, to add or subtract a model from your data. The task to do this is called SDMOD and allows up to four
spatially elliptical Gaussians (or an image) to replace the data, or to be added to the data, with either a Gaussian or
no frequency dependence. When the data are replaced, a random noise may also be added. SDMOD has options for
modeling beam-switched continuum data (set BPARM(1) = 1) as well as for spectral-line data. For
example, to see what a modestly noisy point source at the origin would look like after all of the imaging
steps:
> INDI n ; GETN ctn C R | to select the disk and catalog entry of the data set. |
> NGAUSS 1 ; APARM 0 C R | to get one Gaussian with no frequency dependence. |
> GWIDTH 0 ; GPOS 0 C R | to do a point source (convolved with the single-dish
beamwidth in the header) at the coordinate center. |
> GMAX 1, 0 ; FLUX 0.05 C R | to do a 1 K object with rms noise of 0.05 K. |
> GO C R | to run the task. |
The output file from SDMOD can then be fed to SDGRD, BSGRD, or any other appropriate task as if it were
regular data. The input model is convolved with the single-dish beamwidth given in the uv data header
before being used to replace or add to the input data. The history file will show in detail what was
done.
Beam-switched observations may be modeled with task BSMOD. No input data set is needed. Instead two regular
grids of switched data are constructed from a specified model plus noise and a variety of instrumental
defects.