9.3 Loading, fixing and inspecting data
In theory, 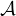
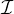
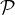
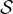 can process data from multiple frequency bands (FQ numbers in parlance) coexisting
within the same data set. However, it is recommended that the data be separated into different frequency bands as
soon as possible after loading the data and process each FQ number separately. If you wish to do this, you should do
it immediately after performing the relevant steps in §9.3. The VLBAUTIL procedures VLBAFQS and VLBAFIX do this
automatically (VLBAFIX is recommended and does other “fixing” tasks like fixing subarrays etc.). If you want to do
this by hand use the task UVCOP.
can process data from multiple frequency bands (FQ numbers in parlance) coexisting
within the same data set. However, it is recommended that the data be separated into different frequency bands as
soon as possible after loading the data and process each FQ number separately. If you wish to do this, you should do
it immediately after performing the relevant steps in §9.3. The VLBAUTIL procedures VLBAFQS and VLBAFIX do this
automatically (VLBAFIX is recommended and does other “fixing” tasks like fixing subarrays etc.). If you want to do
this by hand use the task UVCOP.
9.3.1 Loading data from the VLBA correlator
9.3.1.1 Running FITLD
The information below applies to data from the VLBA Correlator in what the VLBA archive calls
“raw” format, more formally known as FITS-IDI format. The archive now also contains data called
“calibrated” which have been run through a few of the simplest VLBA procedures but which are
nowhere near calibrated. These files are recommended under normal circumstances. They may also be
loaded with FITLD, but the DOCONCAT option does not work with the FITS table format used in the
archive.
Data generated by the VLBA correlator are loaded from DAT (or Exabyte) tape (or from disk files) into
using FITLD. First, physically load your tape and MOUNT it (§3.9), then run FITLD. Often the data on your
tape will be divided into a number of separate files (corresponding to separate “correlator jobs”). In this case, run
FITLD with NCOUNT set equal to the number of files on the tape (or a suitably large number), as listed on the paper
index which comes with the tape. The adverb ANTNAME allows the user to control the antenna numbering if desired.
Also set DOCONCAT = 1 C R to ensure that all tape files with the same structure are concatenated into a single
file. Note that standard tape handling tasks (e.g., PRTTP and TPHEAD) can be used to inspect the tape
contents.
Note that antennas, sources, frequency IDs, and other things may be numbered differently in different correlator
jobs. FITLD fixes all this for you, but only if you set DOCONCAT = 1 and, better still, load as many files as possible in
each execution of FITLD. FITLD can load VLBA correlator data from multiple disk files so long as they have the
same name plus a consecutive post-pended number beginning with 1. If you forget to put all the
related data together with FITLD you can use MATCH to align the antenna numbers followed by DBCON
later.
Typical inputs to FITLD would be:
> INTAPE n C R | to specify the input tape number. |
> NFILES 0 C R | to skip no files on tape. |
> DATAIN ’ ’ C R | to load from tape, not from disk. |
> OUTSEQ 0; OUTDI 1 C R | to specify the sequence number and disk of the output. |
> OPTY ’ ’ C R | to load any type of file found. |
> NCOUNT 20 C R | to load 20 tape files. |
> DOUVCOMP 1 C R | to save disk space by writing compressed data. |
> DOCONCAT 1 C R | to concatenate files with same data structure into one disk file. |
> CLINT △t C R | set CL table interval to △t minutes (see discussion below). |
> DIGICOR 1 C R | to request digital corrections (usually VLBA correlator only). |
> DELCORR 1 C R | to request delay decorrelation corrections (VLBA correlator
only). |
> WTTHRESH 0.65 C R | flag incoming visibilities with correlator weights less than
0.65. |
> DOWEIGHT 1 C R | to have the data weights include channel bandwidth and
integration time as well as correlator weights. |
> TIMERANG 0 C R | to accept data from all times. |
> SELBAND 0 C R | bandwidth to select (kHz). |
> SELFREQ 0; FQTOL 0 C R | frequency to select with tolerance of 10 kHz. |
> OPCODE ’ ’ C R | to not copy the tape statistics table (’VT’ table). |
> GO C R | to run the program. |
This may seem a bit formidable. For straightforward VLBI observations, there is a collection of procedures to
simplify matters including the loading of data. Enter
> RUN VLBAUTIL C R | to acquire the procedures; this need be done only once since
they will be remembered. |
> INTAPE n C R | to specify the input tape number. |
> NCOUNT 20 C R | to load 20 tape files. |
> OUTNAME ’TEST’ ; OUTDI 1 C R | to specify the name and disk of the output file. |
> DOUVCOMP 1 C R | to save disk space by writing compressed data. |
> CLINT △t C R | to set the CL table interval to △t minutes (see discussion
below). |
Because the data files tend to be very large, you will usually write compressed data (DOUVCOMP=1). These files take
about 1/3 of the space of ‘uncompressed’ data sets, but cause information about the weights of individual
polarizations, spectral channels, and IFs to be lost. There is some loss in dynamic range and sensitivity when
the weight information is (partially) compromised. (See Appendix F for an expanded discussion
of when to and when not to write ‘compressed’ data sets.) If your observation has more than one
DAT or Exabyte tape, simply run FITLD for each tape. Setting DOCONCAT 1 and setting the output file
name completely will ensure that the data from separate tapes with compatible observing band/data
structure will be appended to existing files. Generally, after loading all of your data, you will
have one file for each such observing band and/or observing mode. However, observations which
require multiple passes through the correlator will have one file per observing mode per correlation pass.
Data from separate correlator passes can be concatenated using task VBGLU and/or merged with task
VBMRG.
Adverb CLINT, which specifies the CL table time sampling interval, must be short compared to the anticipated
coherence time. CLINT should be set such that the shortest anticipated fringe-fit interval is spanned by a few CL
entries. Time sampling in the CL table that is too coarse can lead to calibration interpolation errors when applying
the fringe-fit solutions at later stages of the data reduction. If the interval is made unnecessarily short the CL table
may become unmanageably large.
It is recommended that corrections for digital representation of the correlated signals be performed in FITLD under
control of adverb DIGICOR, but only for data from the VLBA correlator. DIGICOR should be set to one for all
continuum and nearly all spectral line experiments. Set DIGICOR to 3 or 4 if the digital corrections are desired for a
non-VLBA correlator, e.g., some versions of the DiFX correlator. In the special case of spectra with very strong
narrow features, the absence of correlator zero-padding may limit the accuracy of the quantization corrections. See
the FITLD help file for further information. The details of digital correction for FX correlators can be found in Radio
Science 33, 5, 1289–1296, “Correction functions for digital correlators with two and four quantization levels”, by L.
Kogan.
Adverb DELCORR enables amplitude corrections for known delay decorrelation losses in the VLBA correlator, as
described in Memo 90 (1995, “Delay decorrelation corrections for VLBA data within ” by A. J.
Kemball). Setting DELCORR=1 will create a correlator parameter frequency (CQ) table for each file written by FITLD.
Do this for the VLBA correlator only. The presence of this table enables the delay decorrelation correction once the
residual delays have been determined in fringe-fitting. These corrections will not be applied if the data
were not correlated at the VLBA correlator or if the CQ table is missing. For older FITLD files the CQ
table can be generated using task FXVLB and this must be done before any changes in the frequency
structure of the file are made. The CQ table is used for rate and delay amplitude decorrelation corrections
after residual delay and rate errors have been determined by fringe-fitting, and are being applied to
the data. The CQ table has no immediate effect on the data written by FITLD but is essential for later
processing.
The WTTHRESH adverb can be applied to drop incoming data with playback weights less than the specified limit.
Note that data flagged in this way are unrecoverable except by re-running FITLD. The data weights are normalized to
unity so good data usually have correlator weights close to 1.0. If DOWEIGHT > 0, the actual data weights will be
scaled by twice the product of the channel bandwidth in Hz and the integration time in seconds. This should make
the weights approximately one over the rms squared. You should examine your data carefully if you
use WTTHRESH to make sure that you have not discarded too much data at this stage. Typically 0.8
or higher is good for the VLBA, but for non-VLBA stations a lower value such as 0.6 or 0.7 may be
appropriate.
Calibration data have been transferred from the correlator with your data if your data include VLBA antennas and
were correlated after 1 April 1999 and before late 2009, when the DiFX correlator came on line and your IMHEADER
listing shows the presence of GC, TY, WX, PC and FG tables, as in the example below. If you loaded more than one tape
file, you must merge the calibration tables. VLBALOAD does the merging for you. See §9.3.1.2 for additional details.
Note that, as this example shows, it is possible your data have calibration transfer tables even though they were
correlated before 1 April 1999. If your IMHEADER does not show GC and TY tables, you do not have calibration
transfer and must manually load calibration information in from text files. Also, even if you have calibration
transfer, you may still have to manually load calibration information for some non-VLBA antennas (see
https://science.nrao.edu/facilities/vlba/calibration-and-tools/caliblogs for some information in this
regard).
The output files produced by FITLD are in standard multi-source format (as described in §4.1) and contain data
from all the target and calibrator observations in your observation. FITLD also writes a large number of extension
tables including an index (NX) table, and many tables containing calibration information. A description of the VLBA
correlator table types is given in §9.8. If you are missing the CORR-ID random axis, your release is stale
(pre-15APR97) and you are strongly encouraged to upgrade to the latest release; much of the information presented
in this chapter will not be usable with pre15APR97 releases of . Your catalog header should be similar to
the one, obtained using verb IMHEADER, given below. If you have GC, TY, FG, WX, and PC tables as in
this example data header, your data were processed with calibration transfer - see §9.3.1.2 for more
details.
Image=MULTI (UV) Filename=329 .OVLB . 1
Telescope=VLBA Receiver=VLBA
Observer=TM008 User #= 44
Observ. date=23-SEP-1998 Map date=06-JAN-1999
# visibilities 6567 Sort order **
Rand axes: UU-L VV-L WW-L TIME1 BASELINE SOURCE FREQSEL
INTTIM CORR-ID WEIGHT SCALE
----------------------------------------------------------------
Type Pixels Coord value at Pixel Coord incr Rotat
COMPLEX 1 1.0000000E+00 1.00 1.0000000E+00 .00
STOKES 1 -2.0000000E+00 1.00 -1.0000000E+00 .00
FREQ 16 4.9714900E+09 .53 5.0000000E+05 .00
IF 8 1.0000000E+00 1.00 1.0000000E+00 .00
RA 1 00 00 0 .000 1.00 .000000 .00
DEC 1 00 00 0 .000 1.00 .000000 .00
----------------------------------------------------------------
Coordinate equinox 2000.00
Maximum version number of extension files of type HI is 1
Maximum version number of extension files of type CQ is 1
Maximum version number of extension files of type AT is 1
Maximum version number of extension files of type IM is 1
Maximum version number of extension files of type CT is 1
Maximum version number of extension files of type GC is 1
Maximum version number of extension files of type TY is 1
Maximum version number of extension files of type FG is 1
Maximum version number of extension files of type PC is 1
Maximum version number of extension files of type MC is 1
Maximum version number of extension files of type OB is 1
Maximum version number of extension files of type AN is 1
Maximum version number of extension files of type WX is 1
Maximum version number of extension files of type FQ is 1
Maximum version number of extension files of type SU is 1
Keyword = ’OLDRFQ ’ value = 4.97149000D+09
Note that the sort order of the output data set is listed as ** rather than TB and that there are no attached CL and NX
tables. This happens when FITLD detects what might be a sub-array condition (two frequency IDs or two sources
observed at the same time) on reading the data. In clear cases, the actual simultaneous frequency IDs and sources
will be reported. In this case, FITLD detected the use of multiple integration times on different baselines in
the data set; this is common for SVLBI data. The message reported by FITLD in this case takes the
form:
**********************************************
FITLD5: Subarray or multiple dump-rate condition found.
FITLD5: NX/CL tables deleted.
FITLD5: Use USUBA to set up subarrays.
FITLD5: Rerun INDXR using CPARM(3) and (4)
FITLD5: *******************************************
Unless any of the following criteria are met, the data written by FITLD are immediately ready for further
processing.
- If the sort code has been blanked as in this example, you must sort the data (use UVSRT or MSORT).
- If the source subarray condition is encountered, you may need to run USUBA after doing any ANTAB
that may be needed..
- If the frequency ID subarray condition is encountered, you must separate the frequency IDs into
separate data sets; procedure VLBAFQS will do this for you.
- If FITLD does not leave behind CL and NX tables, you must run INDXR to create them. Procedure
VLBAFIX will do all of the above for you.
- If you wish to join together data processed in multiple correlator passes, you must run VBGLU and/or
VBMRG.
FITLD can also be used to load archived data previously written to tape using either FITTP or FITAB, as
described in §5.1.2. In this case the VLBA correlator-specific adverbs, such as those enabling digital and delay
corrections, are not active.
9.3.1.2 Calibration transfer
Beginning on 1 April 1999, the VLBA correlator attaches calibration information for VLBA and some non-VLBA
antennas directly to the output FITS files. If your IMHEADER listing shows GC, TY, WX, FG, and PC tables, then the
correlator has provided calibration information; this service is called calibration transfer. Note that projects
correlated at slightly earlier dates may also have calibration transfer information. You must have 15APR99 or later
version of to take advantage of calibration transfer. Not all antennas provide all the information needed for
calibration transfer to the VLBA correlator, see
 for
the latest information on this subject. For those antennas for which calibration information was not
transferred by the VLBA correlator, you must process the log files in the traditional way as outlined in
§9.5.2. Calibration for the VLA and the GBT began to be transferred with the FITS files in November
2003.
for
the latest information on this subject. For those antennas for which calibration information was not
transferred by the VLBA correlator, you must process the log files in the traditional way as outlined in
§9.5.2. Calibration for the VLA and the GBT began to be transferred with the FITS files in November
2003.
Between April 1999 and late 2009 the information processed by the correlator was somewhat redundant so that the
calibration tables, the GC table in particular, must be merged using TAMRG, a very general and hence complicated
task. There are a couple procedures to do this for you in the VLBAUTIL package, VLBAFIX and VLBAMCAL, if you have
previously run VLBAFIX your tables have been merged:
> RUN VLBAUTIL C R | to acquire the procedures; this should be done only once since
they will be remembered. |
> INDISK n ; GETN ctn C R | to specify the input file. |
> VLBAFIX C R | to run the procedure. |
X
You should use VLBAFIX after you have finished loading the data from tape, but before you either change the
polarization structure of the data with FXPOL, load any calibration data for non-VLBA telescopes, or apply the
calibration data.
At this point it is a good idea to save the tables that were loaded with your data with TASAV. This protects you from
having to reload the uv data from scratch if one of the original tables is damaged in some way. If you need to copy a
table from the TASAV’ed file use TACOP.
9.3.1.3 Repairing VLBA data after FITLD
As listed above, there are a variety of reasons why VLBA data may need some repair after FITLD has been run. They
may need to be sorted into strict time order, to have the subarray nomenclature corrected, to be split into
different frequencies, to have the polarization structure fixed, and/or to have the original index (NX)
table and calibration ((CL) recreated. These repairs can all be done by the procedure VLBAFIX, which
will examine the data and perform any of the necessary fixes. If the data contain subarrays then the
procedure must be told to split the data into multiple subarrays (SUBARRAY=2), otherwise it will assume no
subarrays and force all the data into one subarray.VLBAFIX is intended to replace VLBASUBS, VLBAFQS,
VLBAMCAL and VLBAFPOL, all of which can be run individually instead. Also we have recommended
in the last few sections that VLBAFIX be run, if you have already run it, it does not need to be run
again.
> RUN VLBAUTIL C R | to acquire the procedures; this should be done only once since
they will be remembered. |
> INDISK n ; GETN ctn C R | to specify the input file. |
> CLINT △t C R | to set the CL table interval to △t minutes (see discussion above
in §9.3.1.1). |
> OUTDISK m C R | to specify the output disk when needed. |
> VLBAFIX C R | to run the procedure. |
Remember that all of the VLBAUTIL procedures have HELP files with good discussions about when to use the simple
procedures and when to use the tasks directly.
9.3.1.4 Sorting and indexing VLBA correlator data
If multiple integration times are used on different baselines, the VLBA correlator will write data that are not in strict
time-baseline (TB) sort order. VLBAFIX (§9.3.1.3) will sort your data if needed, if you want to do the sorting by hand
do the following. In general, task UVSRT can be used to sort randomly ordered uv data files in , but has
significant disk space requirements through the use of intermediate scratch files. A special task, MSORT, has
been written which uses a direct memory sort with sufficiently large buffers to accommodate the
scale over which the data deviate from true time-baseline sort order. No intermediate scratch files are
used and it can be significantly faster than UVSRT for this special case. MSORT competes with UVSRT in
performance even in other cases, particularly when the individual visibility records are large due to many
spectral channels and/or IFs. The inputs to MSORT are similar to those required by UVSRT and take the
form:
> INDISK n ; GETN ctn C R | to specify the input file. |
> SORT ’ ’ C R | to select default sort order (’TB’ or time-baseline). |
> GO C R | to run the program. |
Note that if the input and output file names are identical, the input file is sorted in place. In-place sorting is
dangerous, but may be necessary if there is insufficient disk space for a second copy of the data set or for the
intermediate scratch files required by UVSRT. Never abort an in-place sort in progress because you will destroy the integrity
of your data set.
9.3.1.5 Subarraying VLBA correlator data
If the project was observed without using subarrays (defined as times at which separate antennas are
simultaneously observing different sources or at different frequencies), this step involving USUBA is not necessary and
should be skipped.
If the observations have been scheduled in separate subarrays, defined either by source or frequency selection, the
subarrays should be labeled in before proceeding any further. The VLBA correlator does not conserve
subarray information, which in any event often has no unique characterization. This is specified in using
task USUBA which allows subarrays to be defined through either the input adverbs, an external KEYIN text file,
or through the use of an automatic algorithm to identify and label subarrays found in the data. The
automatic algorithm is recommended, but its results should be checked closely. Note that ANTAB tables do not
know about subarrays that will be assigned by USUBA, so you must run all ANTABs before running
USUBA.
If you have subarrays, they need to be sorted, have the subarray nomenclature corrected, and/or
have the index (NX) table and calibration (CL) version 1 table rebuilt. In this case, there is a simplified
procedure to combine the three repair operation, VLBASUBS. Only use this procedure if you know you have
subarrays.
> RUN VLBAUTIL C R | to acquire the procedures; this should be done only once since
they will be remembered. |
> INDISK n ; GETN ctn C R | to specify the input file. |
> CLINT △t C R | to set the CL table interval to △t minutes. |
The only user-controllable input is the CL table interval; see discussion above. VLBAFIX will perform this operation if
requested (§9.3.1.3).
For automatic subarray labeling by USUBA, representative input parameters would be:
> INDISK n ; GETN ctn C R | to specify the input file. |
> OPCODE ’AUTO’ C R | to identify subarrays automatically. |
> FREQID -1 ; SUBA 0 C R | to include all frequency IDs and subarrays. |
> INFILE ’ ’ C R | to use no external file for subarray identifications. |
> GO C R | to run the program. |
Sometimes FITLD erroneously identifies a subarray condition, usually because of spurious total-power
data points. In such cases, you can set OPCODE = ’ ’ ; SUBARRAY = 1 to force all data into the first
subarray.
In circumstances requiring USUBA, one often wants the calibration in one subarray to apply to other
subarrays. USUBA will make the subarray column have value 0 which means all. Other tasks may not be so
obliging so you may need to use TABED or verb TABPUT to change tables from subarray-specific to
subarray-general.
9.3.1.6 Indexing VLBA correlator data
If FITLD had not written NX or CL tables or it was necessary to sort the data as described in §9.3.1.4, you must run
task INDXR. If VLBAFIX (§9.3.1.3) was run this is done automatically. INDXR will generate an NX table and, if need be,
a CL table. Typical parameters for INDXR are:
> INDISK n ; GETN ctn C R | to specify the input file. |
> PRTLEV 0 C R | to print minimal details of progress. |
> CPARM 0, 0 , △t , 1 C R | to set the CL interval to △t and recalculate the model. |
> GO C R | to run the program. |
Note that CPARM(4) can be set to zero unless the correlator model is required in later reduction (e.g., in astrometry
or geodesy observations) The CL table sampling interval △t should be chosen subject to the same considerations
given regarding adverb CLINT in the discussion of FITLD in §9.3.1.1. VLBAFIX will perform this operation if needed
(§9.3.1.3).
9.3.1.7 Concatenating VLBA correlator data
Sometimes an observation is correlated using multiple passes through the VLBA correlator. In this context, multiple
pass means different IFs/pass; this is due to data rate limitations in the correlator. Be careful to have FITLD load
each pass into a separate disk file; otherwise a very confused data set will be produced. If it is desired to join
together the IFs correlated on each pass, the task VBGLU should be used. VBGLU can only handle data sets
that have the same polarization and spectral channel parameters. In 31DEC21, it can join data sets
from different days while previously it required the oservation date to be the same. If the IFs are not
observed at the same time, the file becomes rather larger due to the many flagged IFs. But, this option
does allow rather different frequencies to be imaged together correctly. Task MATCH may be used to
make the antenna, source, and frequency ID numbers in one data set the same as those in another
data set so that they may be used as inputs to VBGLU. Note that MATCH is very fussy about details. You
may use RESEQ to renumber antennas and RESOU to renumber sources in order to bring data sets into
agreement.
The inputs to VBGLU are rather simple. Each of the input files to be glued together is specified via INNAME–IN4NAME,
and an output file is specified via OUTNAME. The choice of input file 1 is no longer important. No data are lost in the
revised version of this task.
> INDISK n ; GETN ctn C R | to specify the input file. |
> OUTDISK n C R | to specify the output disk. |
> GO C R | to run the program. |
With the changes in recording technology, it is also possible that a correlator will not have enough playback units
for all antennas in an experiment. In this case, multiple correlations will also have to be done in order to correlate
every possible baseline. But, inevitably, certain baselines will appear more than once in these correlations. FITLD
will load all passes into a single data set (if DOCONCAT=1) or separate disk files which may be concatenated, after
MATCH, with DBCON. Note that MATCH is very fussy about details. You may use RESEQ to renumber antennas and RESOU
to renumber sources in order to bring data sets into agreement. Sort the data set into ’BT’ order with UVSRT.
Then task VBMRG may be used to discard any duplicate data. Task DBAPP may be used to avoid the
2n proliferation of files, but only if the files are fairly similar in antennas, subarrays, and frequency
IDs.
9.3.1.8 Labeling VLBA correlator polarization data
The VLBA correlator does not preserve polarization information unless it is operating in full polarization mode.
This results in polarizations not being labeled correctly when both RR and LL polarizations are observed without
RL and LR. Each VLBA correlator band is loaded into as a separate IF and is assigned the same polarization.
FXPOL takes a data set from the VLBA correlator and produces a new data set that has the correct IF and
polarization assignments. Unfortunately, there is no reliable way to determine the polarization of
each IF from the input data set and you must specify the polarization assignments using the BANDPOL
adverb.
Most VLBA setups assign odd-numbered bands to RCP and even-numbered bands to LCP. In this case
BANDPOL should be set to ’*(RL) ’ (the default) and FXPOL will generate a new data set that is of equal
size to the input data set, but has two polarizations and half the number of IFs. This case normally
applies if LISTR shows pairs of IFs with the same frequency and QHEADER shows one pixel on the STOKES
axis with coordinate value RR, but there may be exceptions to this rule when non-VLBA antennas are
used.
There is a procedure for use with VLBA-only data that attempts to determine which of the above cases applies and
then runs FXPOL for you, if you ran VLBAFIX (§9.3.1.3) this has already been done:
> RUN VLBAUTIL C R | to acquire the procedures; this should be done only once since
they will be remembered. |
> INDISK n ; GETN ctn C R | to specify the input file. |
Use VLBAFPOL to check whether you need to relabel the polarizations in your data after loading the data, looking for
subarrays, and merging redundant calibration data, but before reading any calibration data from non-VLBA
stations. VLBAFPOL assumes that all of your FREQIDs have similar polarization setups. For this reason, you should
normally run VLBAFPOL after copying each frequency ID to a separate file using VLBAFQS (§9.5). This strategy also
reduces the amount of disk space needed for VLBAFPOL.
To use FXPOL directly, typical inputs are:
> INDISK n ; GETN ctn C R | to specify the input file. |
> BANDPOL ’*(RL)’ C R | to specify the normal VLBA polarization structure. |
> GO C R | to run the program. |
Consult HELP FXPOL for further information about more complicated cases. Note that FXPOL has to write a new
output file since the structure of the data is being changed. All standard extension files are also converted, but it is
still a good idea to run FXPOL before running the calibration tasks.
In single-polarization observations, LL data may simply be mis-labeled as RR or vice-versa. This does not need to
be corrected within but the user needs to take this into account when selecting or calibrating the data,
particularly in specifying the polarization in the amplitude calibration text file (§9.5.2). The Stokes axis can however
be modified. Before running PUTHEAD, you should run IMHEAD to check which axis is the Stokes axis in the catalog
header.
> INDISK n ; GETN ctn C R | to specify the input file. |
> KEYWORD ’CRVALm’ C R | to select the Stokes or mth axis in the header. |
> KEYVALUE = -2 C R | to set the Stokes value to ’LL’ (or -1 for ’RR’). |
> PUTHEAD C R | to set the coordinate value. |
9.3.1.9 Ionospheric corrections
At low frequencies (2 GHz and lower) the ionosphere can cause large unmodeled dispersive delays, seen as rapid
phase wrapping. This can be of particular importance in phase referencing observations, where phases must be
interpolated over weak sources. Even at high frequencies (e.g., 8 GHz) the ionosphere can be important,
depending on the experiment and the condition of the atmosphere during the observation. One way to remove at
least some of the ionospheric phase offsets is by applying a global ionospheric model derived from GPS
measurements. The task TECOR processes such ionospheric models that are in standard format known as
the IONEX format. These models are available from the Crustal Dynamics Data Information System
(CDDIS) archive. There is a procedure which is part of VLBAUTIL, called VLBATECR that automatically
downloads the needed IONEX files from CDDIS and runs TECOR. It will examine the header and the
NX table and figure out which dates need to be downloaded, so the observation date in the header
must be correct and an NX table must exist. See EXPLAIN VLBATECR for other requirements. TECOR also
determines the ionospheric Faraday rotation which is applied in the calibration of the cross-hand
visibilities.
> RUN VLBAUTIL C R | to acquire the procedures; this should be done only once since
they will be remembered. |
> INDISK n ; GETN ctn C R | to specify the input file. |
You can also download the files manually from the CDDIS archive through anonymous ftp and run VLBATECR or
TECOR, see EXPLAIN TECOR for detailed instructions on how to retrieve the models. TECOR interpolates
between the maps of electron content in the ionosphere; therefore IONEX files must be retrieved to
cover the entire experiment. Presently, each IONEX file contains maps every 2 hours from hours 00:00
to 24:00. Before November 2002, they contained maps every 2 hours from hours 1:00 through 23:00.
Therefore, for example, if an experiment prior to November 2002 started at 0:00 then files must be
retrieved for the day of the experiment and the previous day so the times between 0:00 and 0:59 can be
interpolated. More recent experiments require two or more files only if they occurred in two or more
days.
Typical inputs to TECOR are:
> INDISK n ; GETN ctn C R | to specify the input file. |
> INFILE ’FITS:JPLG1230.01I’ C R | to set the name of the IONEX file. If there is more than one
file, this name must be a standard format and be the first file.
See EXPLAIN TECOR for more details. |
> NFILES n C R | to set number of IONEX files to be read. |
> SUBARRAY 0 C R | to process all subarrays. This option allows you to process
subarrays used on different dates. |
> ANTENNAS 1 2 3 4 6 7 8 9 10 C R | to find corrections for all antennas except antenna 5 in a ten
antenna experiment. This is important because if the IONEX
models do not cover an antenna and it is not excluded here
then all the solutions for that antenna will be undefined and
the data flagged when the CL table is applied. |
> GAINVER 1 C R | to apply corrections to the first CL table. |
> GAINUSE 2 C R | to create CL table 2 with the corrections. |
> APARM 1 0 C R | to correct for dispersive delay; otherwise only the ionospheric
Faraday rotation will be corrected. |
> GO C R | to run TECOR, correcting for the ionosphere in a new CL table. |
The dispersive delays should be checked using EDITA (option DODELAY=3), SNPLT (options INEXT ’CL’; INVERS 2;
OPTY ’DDLY’) and VPLOT (options BPARM 0; APARM 0; DOCAL 1; GAINUSE 2). TEPLT plots parameters from the
TE table written by TECOR, in particular the Faraday rotation, total electron content, and dispersive
delay. It can also plot the difference of two TE tables in multiple parameters. MFIMG can be used to
make an image cube of the IONEX data after which TVMOVIE and other image display tools will let
you examine the data given to TECOR. TECOR is only as good as the models, which at this time are
quite rough. Therefore, it is a very good idea to compare the corrected and uncorrected phases using
VPLOT.
Extensive studies have revealed that TECOR usually over-corrects data. It removes the time-dependent IFRM, but
leaves behind an extra rotation measure that changes some with obsering date and very slightly with source. A
package of software called ALBUS has been found to give somewhat better solutions for the IFRM. In
31DEC24 a task also named ALBUS was written to invoke this package to correct uv data including
dispersive delay which is important to VLBI data. Unfortunately, the complications of this package
require the Linux operating system and an outside program called apptainer. See EVLA Memo 235 for
details.
CLCOR has a OPCODE = ’IONO’ to make delay corrections for the ionosphere, similar to the ’ATMO’ operation which
is for the atmosphere (§9.5.7.5).
9.3.1.10 Corrections to the Earth Orientation Parameters
This correction is only useful for experiments correlated at the VLBA correlator. VLBI correlators must use
measurements of the Earth Orientation Parameters (EOPs) to take them out of the observations. These change
slowly with time and therefore the EOPs used by the correlator must be continually updated. From 5-May-2003 to
9-Aug-2005 the VLBA correlator used old predicted EOPs which could be significantly wrong and will effect all
phase referencing experiments. Incorrect EOPs can both move the position and possibly smear the target of a phase
referencing experiment. Self-calibration can improve the smearing. Even outside the above quoted period of
particularly bad EOPs, the EOPs can be off so it is recommended that all phase-referencing experiments,
particularly astrometry experiments should have their EOPs corrected. CLCOR (OPCODE=’EOPS’) can do this
correction. It uses the CT table which is only produced by the VLBA correlator, so at the moment CLCOR can only
correct experiments processed at the VLBA correlator. CLCOR also uses a file of measured EOPs, which
can be downloaded from NASA (see EXPLAIN CLCOR for details). There is a procedure which is part
of VLBAUTIL, called VLBAEOPS, which downloads the file automatically and runs CLCOR. To run the
procedure:
> RUN VLBAUTIL C R | to acquire the procedures; this should be done only once since
they will be remembered. |
> INDISK n ; GETN ctn C R | to specify the input file. |
> INFILE ’ ’ C R | to automatically download file. |
The procedure will correct the highest CL version while copying it to a version one higher.
If multiple days have been concatenated, you should run CLCOR manually. Download the file using the instructions
in CLCOR’s explain file. Sample inputs are as follows:
> INDISK n1 ; GETN ctn C R | to specify the input file. |
> OPCODE ’EOPS’ C R | to select correction of the EOPs. |
> GAINVER clin C R | CL table to read, new default is the current highest version. |
> INFILE ’FITS:usno_finals.erp C R | to specify file with correct EOPs — note missing close quote
to retain lower case letters. |
> CLCORPRM(2) dd C R | to use dd days worth of data following the start date from the
USNO file. Set dd to about 4 days more than your last day of
data. |
> GO C R | to run the program. |
In case the automatic download fails, VLBAEOPS can use the file which you have downloaded manually.
9.3.1.11 Preparing the OB table for SVLBI data
The spacecraft orbit table (OB) as produced by FITLD contains the spacecraft position (x,y,z) and velocity
(vx,vy,vz) as calculated to high accuracy from the JPL reconstructed orbit using the SPICE package
(developed at JPL). These quantities are calculated by the correlator on-line software and are passed directly
through to via FITLD by the VLBA correlator. The orbit table is indexed on time and can include
information such as the angle between the spacecraft pointing direction and the Sun, the time since
the start and end of the last eclipse, and the spacecraft parallactic angle. The latter quantities are not
available to the correlator on-line software and, if desired, need to be computed separately for later use in
by task OBTAB. Additionally OBTAB stores orbital elements in the AN table; these are essential
for later use in plotting or inspecting spacecraft orbit information. Sample inputs for OBTAB, are as
follows:
> INDISK n ; GETN ctn C R | to specify the input file. |
> INVERS 1 C R | to process OB table 1. |
> SUBARRAY 1 C R | to select subarray number. |
> APARM 1, 0 C R | to update orbital elements in AN table |
> GO C R | to run the program. |
Note that APARM(8) can be used to directly specify which antenna is the orbiting antenna (this task assumes there is
only one orbiting antenna).
Task OBTAB determines mean orbital elements from the OB table using the spacecraft positions and velocities
and updates the AN table under control of APARM(1). The orbital elements can be examined by using
PRTAB to review the updated AN table. The mean elements are used to compute uv coordinates for the
spacecraft so that model amplitudes AND closure phases and amplitudes can be plotted (by tasks VPLOT,
CLPLT, and CAPLT). The orbit table can be plotted using task OBPLT. Alternatively, the task TAPLT can
be used to display individual columns. Use PRTAB to determine the names of the columns you wish
plotted.
9.3.1.12 Loading the time corrections file for SVLBI data
The round-trip residual delay measurements determined by the tracking stations are supplied to the correlator in
FITS format. These so-called delta-T tables are not passed to by the correlator but can be loaded
indirectly. This table might be used, for example, to plot the time correction as a function of time. Such
information could be useful if a user suspects a loss of coherence due to a poor predicted orbit or a
clock jump at the tracking station. The table contains no internal time stamps, so the row number
must be used to determine the approximate time of a given entry (there are typically 10 rows per
second).
The delta-T tables can be loaded at present using FITLD and attached to a null uv data file, using input parameters
as follows:
> OUTDISK n C R | to specify a separate output file. |
> DATAIN ’FITS:3551708.kct.a C R | to specify the external FITS file. |
> GO C R | to run the program. |
The other FITLD adverbs are not relevant in this instance. Note that lower case letters can be used in the DATAIN
adverb if the trailing quotation mark is omitted. FITLD will load the external FITS file successfully but will print an
error message complaining that no array geometry table was found. This message can be ignored in this
case. The delta-T table will appear as an unknown table of type UK, and can be plotted using task
TAPLT